AutoPart
Semiautomated partner search support for technology transfer using machine learning methods.
Project Objectives:
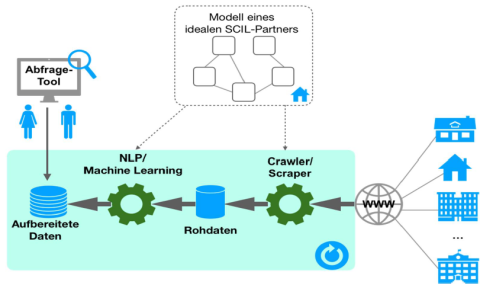
The objective of the AutoPart project is to develop matching algorithms for semi-automatic support in the search for potential partners with whom collaboration can be sought. Based on a partner profile, information on potential partners is searched for in various sources in order to classify them accordingly.
A first application scenario is the support of the search for research partners for technology transfer. Based on a first application example, the technology transfer of simulation and control technology of our project partner DLR SCIL (Systems and Control Innovation Lab), the new matching algorithms will be tested. On the basis of the matching algorithms, a new procedure is to be implemented that will support the initiation of research projects. In a further development stage, a generic tool for semi-automatic support in partner search via matching algorithms is envisaged.
Procedure:
For matching, properties were first identified that make it possible to describe the partners sought in a profile. These characteristics include:
- Company size
- List of industries
- List of regions
- List of fields of activity
- List of core competencies
- Ability to innovate
- Willingness to cooperate.
While some properties are quite easy to determine (e.g., company size, industries), others can be classified as rather complex. For example, the automated assessment of innovative capability proves to be complex. Various individual characteristics such as the number of ongoing research projects, participation in research initiatives and the search for dedicated personnel can provide information about a company's innovative capability. The situation is similar with the willingness to cooperate.
Therefore, to compile a company profile that can be used for classification, a crawling/scraping of different sources (existing websites, job postings, job portals, company catalogs) is performed. The collected unstructured data is processed with classical techniques from Natural Language Processing (NLP) to build up relevant feature vectors for further analysis. These feature vectors serve as a basis for a classification (matching) of the considered companies with algorithms for supervised machine learning. For the classification, individual classifiers are to be developed first for each feature, which are then to be combined into an ensemble classifier in order to determine an overall classification (the target variable is the suitability as a cooperation partner) of a company in relation to the search query.
Ongoing Work:
The technical analysis and also the data modeling are largely completed. The development of the classification system is iterative, integrating several final theses (bachelor and master theses) as well as seminar papers.
Used technology and toolset:
- Programming languages: Python, Java
- Web technologies: TypeScript, Angular
- Webcrawling and -scraping: Scrapy, BeautifulSoap
- Machine Learning and NLP: Scikit-learn, nltk, spacy
- Databases: MariaDB, Elasticsearch
- Development environment: Pycharm, jupyter, Eclipse
- Version management: GitHub
Funding code:
01IO1911
Project partner:
German Aerospace Center
SCIL (Systems and Control Innovation Lab) Munich University of Applied Sciences
Competence Center Business Informatics (CCWI)
Project funding:
Federal Ministry of Education and Research