AutoPart
Semiautomatisierte Unterstützung der Partnersuche für den Technologietransfer unter Nutzung von Machine Learning Methoden
Zielsetzung des Projekts:
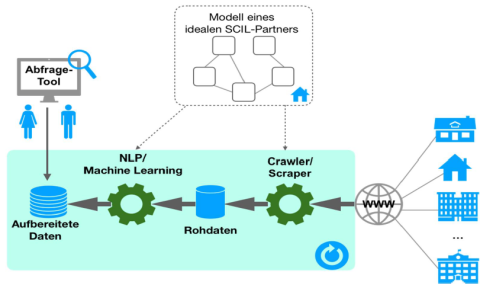
Ziel des Projektvorhabens AutoPart ist die Entwicklung von Matching-Algorithmen zur semi-automatischen Unterstützung bei der Suche nach potenziellen Partnern, mit denen eine Zusammenarbeit angestrebt werden kann. Auf der Basis eines Partnerprofils wird in verschiedenen Quellen nach Informationen zu potentiellen Partnern gesucht, um diese entsprechend zu klassifizieren.
Ein erstes Anwendungsszenario ist die Unterstützung der Suche von Forschungspartnern für den Technologietransfer. Anhand eines ersten Anwendungsbeispiels, dem Technologietransfer von Simulations- und Regelungstechnik unseres Projektpartners DLR SCIL (Systems and Control Innovation Lab) sollen die neuen Matching-Algorithmen erprobt werden. Auf der Basis der Matching-Algorithmen soll ein neues Verfahren realisiert werden, das bei der Anbahnung von Forschungsprojekten unterstützt. In einer weiteren Ausbaustufe ist ein generisches Tool zur semi-automatischen Unterstützung bei der Partnersuche über Matching-Algorithmen angedacht.
Vorgehensweise:
Für das Matching wurden zunächst Eigenschaften identifiziert, die es ermöglichen, die gesuchten Partner in einem Profil zu beschreiben. Zu diesen Eigenschaften zählen:
- Unternehmensgröße
- Liste von Branchen
- Liste von Regionen
- Liste von Tätigkeitsfeldern
- Liste von Kernkompetenzen
- Innovationsfähigkeit
- Kooperationsbereitschaft
Während einige Eigenschaften recht einfach ermittelbar sind (z. B. Unternehmensgröße, Branchen), sind andere als eher komplex einzustufen. Beispielsweise erweist sich die automatisierte Beurteilung der Innovationsfähigkeit als aufwändig. Verschiedene Einzelmerkmale wie die Anzahl laufender Forschungsprojekte, die Beteiligung an Forschungsinitiativen und die Suche nach dediziertem Personal können über die Innovationsfähigkeit eines Unternehmens Auskunft geben. Ähnlich verhält es sich mit der Kooperationsbereitschaft.
Für die Zusammenstellung eines Unternehmensprofils, das für eine Klassifizierung herangezogen werden kann, wird daher ein Crawling/Scraping verschiedener Quellen (existierende Webseiten, Stellenausschreibungen, Job-Portale, Firmenkataloge) durchgeführt. Die gesammelten, unstrukturierten Daten werden mit klassischen Techniken aus dem Natural Language Processing (NLP) bearbeitet, um für eine weiterführende Analyse relevante Merkmalsvektoren aufzubauen. Diese Merkmalsvektoren dienen als Basis für eine Klassifizierung (Matching) der betrachteten Unternehmen mit Algorithmen für das überwachte Machine Learning. Für die Klassifizierung sollen je Eigenschaft zunächst einzelne Klassifizierer entwickelt werden, die anschließend zu einem Ensemble Classifier kombiniert werden sollen, um eine Gesamtklassifizierung (Zielgröße ist die Eignung als Kooperationspartner) eines Unternehmens in Bezug zur Suchanfrage zu ermitteln.
Laufende Arbeiten:
Die fachliche Analyse und auch die Datenmodellierung sind weitgehend abgeschlossen. Die Entwicklung des Klassifizierungssystems erfolgt iterativ, wobei mehrere Abschlussarbeiten (Bachelor- und Masterarbeiten) sowie Seminararbeiten integriert werden.
Verwendetes Technologie- und Toolset:
- Programmiersprachen: Python, Java
- Web-Technologien: TypeScript, Angular
- Webcrawling und -scraping: Scrapy, BeautifulSoap
- Machine Learning und NLP: Scikit-learn, nltk, spacy
- Datenbanken: MariaDB, Elasticsearch
- Entwicklungsumgebung: Pycharm, jupyter, Eclipse
- Versionsverwaltung: GitHub
Förderkennzeichen:
01IO1911
Projektpartner:
- Deutsches Zentrum für Luft- und Raumfahrt
- SCIL (Systems and Control Innovation Lab) Hochschule München
- Competence Center Wirtschaftsinformatik (CCWI)
Projektförderung:
Bundesministerium für Bildung und Forschung