Wald5Dplus
Hintergrund
Fernerkundung ist vielseitig geworden. Es gibt weder den einen Sensor noch die eine Plattform für alle denkbaren Anwendungen, sondern für jede Anwendung eine Vielzahl von möglichen Aufnahmesystemen. Die Sensoren unterscheiden sich dabei in der verwendeten Wellenlänge (sichtbares Licht, Infrarotstrahlung, Mikrowellen), in der Beleuchtung (aktiv oder passiv) und in der Aufnahmegeometrie (Punktwolke, Zentralprojektion, Parallelprojektion, Abstandsprojektion). Die Auswahl an Plattformen reicht von der fest montierten Kamera über unbemannte Flugobjekte (UAV), Flugzeuge und Hubschrauber bis hin zu Satelliten und Raumstationen.
Die beiden grundlegenden aus der Wahl der Plattform resultierenden Unterscheidungen sind der Abstand zum beobachteten Objekt und die Wiederholrate, d.h. in welchem zeitlichen Abstand exakt die gleiche Aufnahme wiederholt werden kann, um Änderungen zu erkennen. Will man dieses breite Spektrum an Daten in seiner ganzen Fülle nutzen, braucht man fortschrittliche Ansätze zur Datenfusion und automatischen Interpretation.
Methoden des maschinellen Lernens haben sich – nicht nur in der Fernerkundung – dafür etabliert, erfordern aber ihrerseits wieder extrem große Trainingsdatensätze, um die syntaktischen Muster zu lernen und mit ihrer semantischen Bedeutung zu verknüpfen. Solche Trainingsdatensätze sind im Fernerkundungsbereich noch Mangelware, da die Referenzdaten zur eindeutigen Zuordnung einer Semantik in Form von sogenannten Labels meist fehlen. Deren Beschaffung ist extrem zeit und kostenintensiv und übersteigt das übliche Budget eines Fernerkundungsprojekts.
Ziele
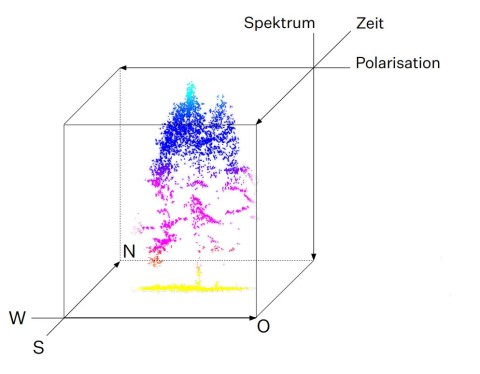
Das vom Raumfahrtmanagement des Deutschen Zentrums für Luft- und Raumfahrt e.V. mit Mitteln des Bundesministeriums für Wirtschaft und Energie geförderte Projekt „Wald5Dplus“ erstellt einen syntaktischen Trainingsdatensatz aus multitemporalen Sentinel-1- und Sentinel-2-Satellitenaufnahmen und vergibt den einzelnen Elementen semantische Labels, die aus Befliegungen abgeleitet worden sind. Die Satellitenmissionen Sentinel-1 (C-Band Synthetic Aperture Radar) und Sentinel-2 (Multispectral Imager) gehören zum Copernicus Programm der Europäischen Kommission und der Europäischen Weltraumorganisation. Sie liefern (bei Sentinel-2 leider wetterabhängig) wöchentliche Aufnahmen in einem 10-m-Raster von ganz Europa, die jedem potenziellen Nutzer frei zur Verfügung stehen. In einem Jahr kommen also um die sechzig Bilder pro Satellit zusammen. Im Rahmen dieses Projekts werden für drei ausgewählte Waldgebiete die Rasterwerte in Nord-Süd-Richtung (erste Dimension), in Ost-West Richtung (zweite Dimension), polarimetrisch durch Sentinel-1 (dritte Dimension), spektral durch Sentinel-2 (vierte Dimension) über die Zeit (fünfte Dimension) in einem Analysis Ready Data Cube zusammengefasst und mit semantischen Labels („plus“) versehen. Die Labels stammen aus Befliegungen der Testgebiete mit Flugzeug- bzw. UAV-getragenen Laserscannern und Multispektralkameras und haben daher eine sehr hohe räumliche Auflösung. Sie sollen Informationen über gewisse Waldparameter wie Baumart, Baumanzahl, Kronenfläche, Kronenhöhe und Kronenanfangshöhe liefern. Die Auswertung der Punktwolken erfolgt mit eigens dafür entwickelten, patentierten Algorithmen und resultiert in den benötigten semantischen Labels, die anschließend auf das räumliche Gitter der Satelliten daten aggregiert werden.
Anhand des Data Cubes werden Methoden des maschinellen Lernens vortrainiert, um in anderen Projekten Verwendung zu finden. Das Gesamtpaket wird als Benchmark-Datensatz über die CODE-DE-Plattform allen interessierten Wissenschaftlerinnen und Wissenschaftlern weltweit kostenlos zugänglich gemacht.
Bisherige Ergebnisse
Zum Ende der Projektlaufzeit werden für drei Untersuchungsgebiete im Nationalpark Bayerischer Wald, im Landesaboretum „Weltwald Freising“ und im Steigerwald Analysis Ready Data Cubes mit wöchentlichen Aufnahmen von Sentinel-1 und Sentinel-2 über den Zeitraum von zwei Jahren zur Verfügung stehen. Um den Speicherplatz zu reduzieren und eine einfachere Interpretation zu ermöglichen, werden die Aufnahmen auf hyperkomplexen Basen polarimetrisch, spektral und temporal fusioniert. Zusätzlich wird jedem Bildelement ein typischer Waldparameter wie z.B. die Anzahl an Bäumen, der Anteil an Laub- bzw. Nadelwald, die mittlere Kronenhöhe etc. zugeordnet sein.
Dieser Datensatz wird mit Methoden der multivariaten Statistik und des maschinellen Lernens eingehend analysiert, um einerseits die Datenaufbereitung und andererseits die Übertragung des Gelernten auf andere Gebiete zu optimieren. Sämtliche Ergebnisse werden zudem in internationalen Fachzeitschriften frei zugänglich (open access) veröffentlicht. Der Datensatz samt vortrainierten Algorithmen soll fortan als Benchmark dienen, an dem sich Neuentwicklungen im Bereich der künstlichen Intelligenz messen können. Im optimalen Fall kann ein ausreichend validierter KI-Algorithmus angeboten werden, der allein aufgrund von Aufnahmen aus den Sentinel-1- und Sentinel-2-Missionen die eingebrachten Waldparameter schätzen kann.
Ausblick
Mithilfe dieses Benchmark-Datensatzes lassen sich zukünftig KI-Algorithmen konsistent einordnen. Sie trainieren alle auf demselben Analysis Ready Data Cube mit denselben Labels und prädizieren die Waldparameter für dieselben syntaktischen Signaturen. Dann entscheiden nur noch Genauigkeit der Zuordnung und Performanz des Algorithmus über den jeweiligen Listenplatz.
Auf diese Weise kann der State of the Art erstmals objektiv evaluiert werden. So könnte man aus der Liste möglicher Kandidaten beispielsweise den optimalen Algorithmus selektieren, um flächendeckend eine thematisch feingliedrige Waldkartierung auf Basis der frei zugänglichen Daten von Sentinel-1 und Sentinel-2 durchzuführen. Auch unerwartete Änderungen wie Waldschäden durch Krankheiten, Schädlingsbefall oder Unwetter könnten zeitnah detektiert werden, um rechtzeitig Gegenmaßnahmen ergreifen zu können, die eine weitere Ausbreitung und somit einen größeren finanziellen Schaden verhindern.
Methodisch bietet der Benchmark-Datensatz die optimale Ausgangslage sowohl für die Validierung der bereits veröffentlichten Algorithmen zur Datenfusion auf hyperkomplexen Basen und zur thematischen Interpretation via Histogramm-Klassifizierung als auch für die Entwicklung neuer oder die Anpassung vorhandener Algorithmen des maschinellen Lernens für die Anwendung in der forstlichen Fernerkundung sowie weit darüber hinaus.
Zuwendungsgeber
Bundesministerium für Wirtschaft und Klimaschutz
Publikationen
Schmitt, A., Wendleder, A., Kleynmans, R., Hell, M., Roth, A., Hinz, S., Multi-Source and Multi-Temporal Image Fusion on Hypercomplex Bases. Remote Sens. 2020, 12, 943. (https://www.mdpi.com/2072-4292/12/6/943)
Krzystek, P., Serebryanyk A., Schnörr, Cl., Cervenka, J., Heurich, M., Large-scale mapping of tree species and dead trees in Šumava National Park and Bavarian Forest National Park using lidar and multispectral imagery. Remote Sensing 2020, 12(4), 66.1. (https://doi.org/10.3390/rs12040661)
Schmitt, A., Sieg, T., Wurm, M., Taubenböck, H. , Investigation on the separability of slums by multi-aspect TerraSAR-X dual-co-polarized high resolution spotlight images based on the multi-scale evaluation of local distributions, International Journal of Applied Earth Observation and Geoinformation, Volume 64, February 2018, Pages 181-198, ISSN 0303-2434. (https://doi.org/10.1016/j.jag.2017.09.006)